


Introduction
I wrote a post before regarding how I archive Zoom lecture recordings, whether I am teaching or someone else is. However, post-recording, those files sit in the vault unedited. It took a few months, but I discovered an issue with the audio in them. Funny. The times that I don't check audio prior to recording are the times it always goes wrong. It's Sod's law. With the audio messed up, and no chance to re-record, is recovery possible?
Let's analyse the situation. They are MKV files with a single video stream
encoded via h264_nvenc. Ok, nothing wrong there. There's 3
audio streams saved as lossless FLAC. Here's the ffmpeg stderr
output (yes, it goes to stderr) for one of the files:
Input #0, matroska,webm, from '2020-11-19 16-23-40.mkv':
Metadata:
ENCODER : Lavf58.29.100
Duration: 01:33:28.85, start: 0.000000, bitrate: 2389 kb/s
Stream #0:0: Video: h264 (Main), yuvj420p(pc, bt709/unknown/unknown, progressive), 1920x1080 [SAR 1:1 DAR 16:9], 62.50 fps, 60 tbr, 1k tbn, 120 tbc (default)
Metadata:
DURATION : 01:33:28.850000000
Stream #0:1: Audio: flac, 48000 Hz, 7.1, s16 (default)
Metadata:
DURATION : 01:33:28.800000000
Stream #0:2: Audio: flac, 48000 Hz, 7.1, s16 (default)
Metadata:
DURATION : 01:33:28.800000000
Stream #0:3: Audio: flac, 48000 Hz, 7.1, s16 (default)
Metadata:
DURATION : 01:33:28.800000000I told OBS to record 3 audio sources so I would have proper separation. It didn't listen to me. These three audio tracks incorrectly contain the following information:
- Track 1: Zoom + Desktop Audio (7.1) + Desktop Audio (LR)
- Track 2: Zoom + Microphone + Desktop Audio (LR)
- Track 3: Zoom + Desktop Audio (LR)
I intended on this being the proper separation:
- Track 1: Zoom
- Track 2: Microphone
- Track 3: Desktop Audio (7.1)
By the way... yes, I now know about the mixer in OBS. That's not going to fix footage that's already been recorded though. I've properly configured OBS for future recordings, if I ever have to use it again. Everyone who records has had audio issues at least once. This is simply my solution to my problem.
The "Trick"
Simply put, if two lossless audio files contain the same sounds, you can cancel those out by inverting one of the waveforms and then mixing it with the other waveform.
I like to show by example. Let's say I had 2 audio files (you can download them to follow along, by the way):
- file_a.flac: Contains a drum kick
- file_ab.flac: Contains a drum kick and a hat
file_ab.flac is the mix of file_a.flac
and a mysteriously lost file_b.flac. Is it possible to recover
it? Yes. Simply invert file_a.flac and mix it into
file_ab.flac. The waveforms will cancel out the kick sound.
Only the hat sound will remain.
Walkthrough via Audacity
Audacity is a wonderful (and
free) tool for the job. I don't often show a step-by-step of it, but here
you go. Open Audacity and drag both file_ab.flac and
file_a.flac in. Should look like this:
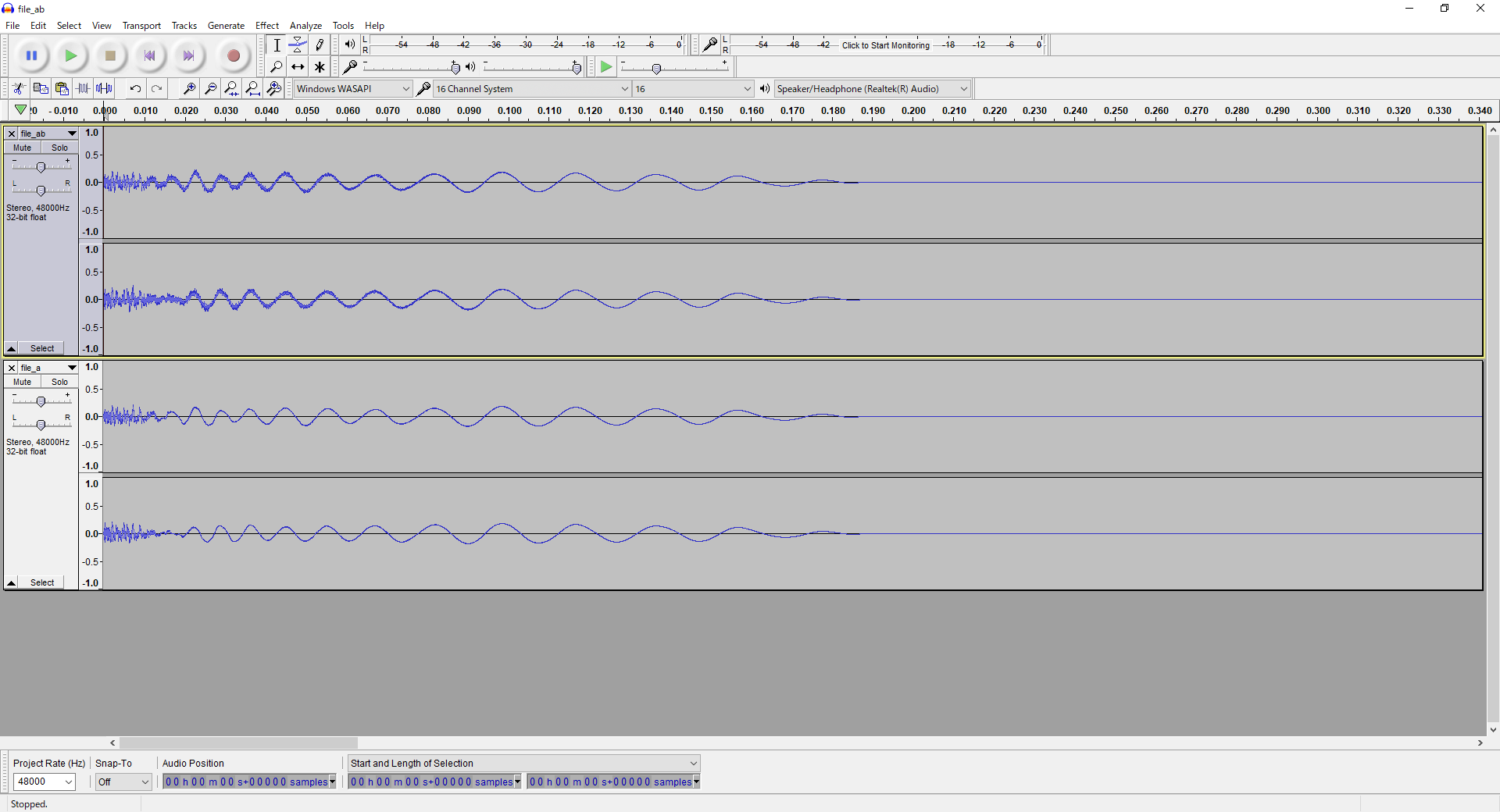
file_ab.flac and file_a.flac loaded into
Audacity.
Select the file_a track by simply clicking on the track's box
to the left of the waveform (click between the 32-bit float
text and the Select box shown below it). You will see the
entire track highlight grey:
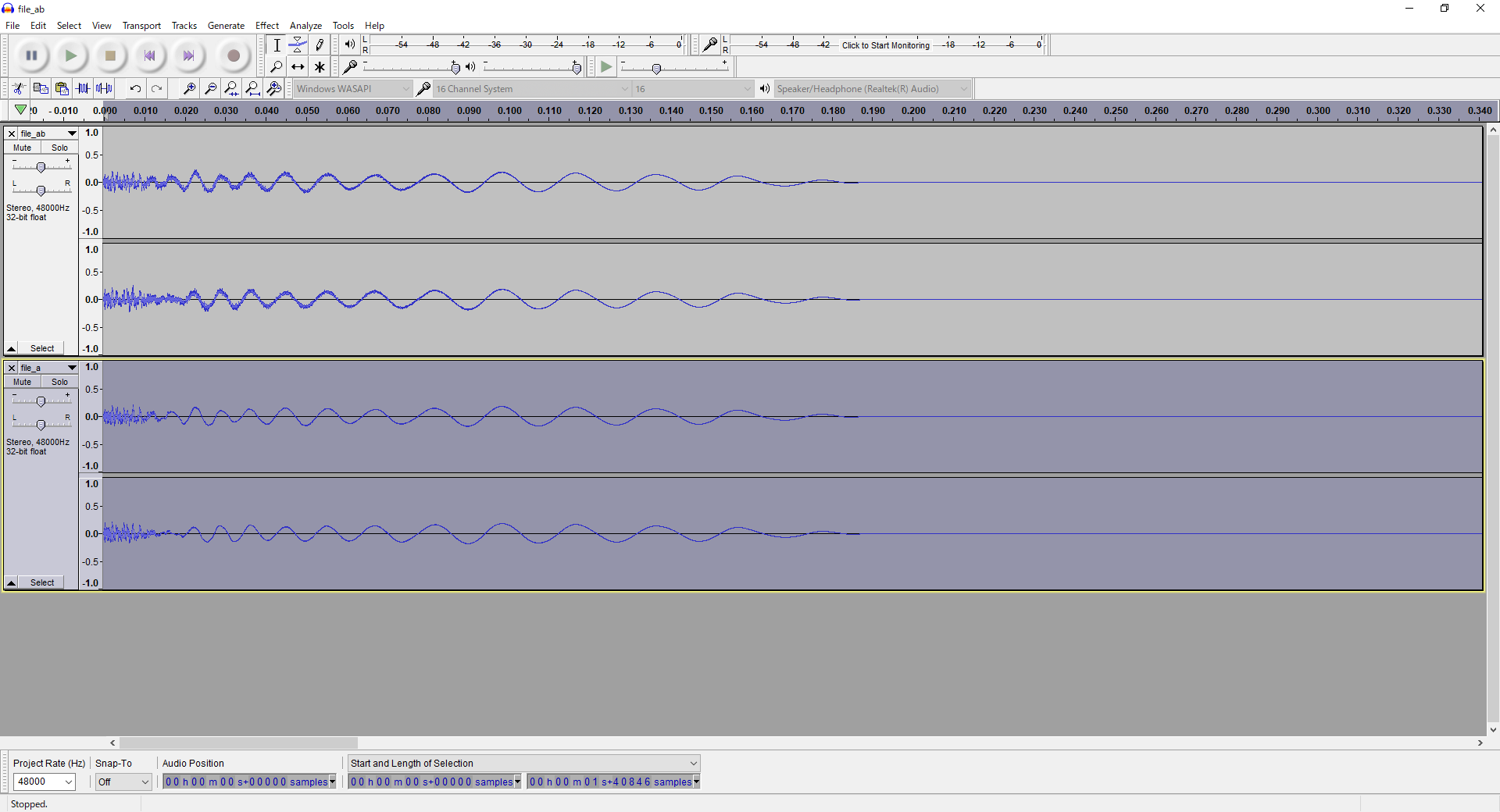
file_a track has been selected.
Next, go up to the top of the screen. Select "Effect" and select "Invert". This will flip the waveform we selected up above.

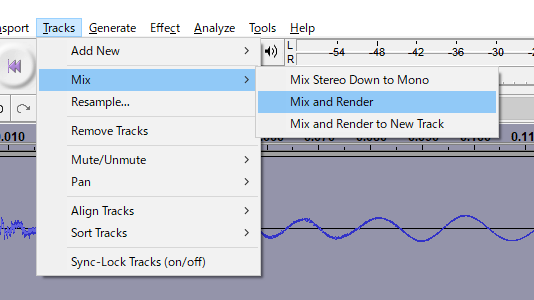
Lastly, let's merge those two tracks together. Press Ctrl + A to select all tracks. Then, go up to the top again. Select "Tracks", "Mix", "Mix and Render".
Congratulations. We have recovered file_b.flac. Play the
audio and you will only hear the hat sound played.
Walkthrough via FFmpeg
As always, FFmpeg is easier and
simpler. This isn't even a walkthrough. It simply mixes the two together by
subtracting file_a.flac from file_ab.flac, which
is essentially inversion.
UNIX> ffmpeg -i "file_ab.flac" -i "file_a.flac" -filter_complex "[0:a:0][1:a:0]amerge=inputs=2,pan=stereo|c0=c0-c2|c1=c1-c3[mix]" -map "[mix]" "file_b.flac"Why does this work?
Audio mixing is simple. To mix two tracks together, you simply perform addition on the two waveforms. The resulting waveform plays both sounds at the same time.
Assume A is file_a.flac, B is
file_b.flac, and C is file_ab.flac:

It would make sense, then, that subtracting from C can give either
A or B respectively. But, you need either A or
B to perform the subtraction. Hence:


It's like this. 2 + 2 = 4. But if we were given just 4 and asked what
two numbers made it, we don't know if that's 2 + 2, 1 + 3, 3 + 1, 0 + 4,
etc. So you must absolutely have either A or B to get the
other out of C.
Now, I am sure you are probably heavily intimidated by this extremely advanced math, so we'll back off from it now.
"So, if I had an instrumental, I can separate vocals from a song?"
If you want a simple answer, yes. Yes you can. But even with the audio being lossless, it probably won't be a perfect extraction of vocals. This can be due to many things done in mastering, like compression (makes audio sound louder) being applied to both files prior to distribution. If compression was applied, you will hear crackling and pop sounds throughout the separated track.
"Do the files really need to be lossless?"
Yes. This goes beyond the FLAC vs MP3 internet fights I often see. While lossy formats intend to only get rid of inaudible portions of the file, you definitely will notice artifacting in your inversion if any of the files used are lossy. They will sound like white noise. The higher the quality, the less the white noise. You can get desirable results if you don't mind it being "good enough", but it won't be perfect.
Recovery via Waveform Inversion... Is it possible?
Time to get back on track. Let's see what those messed up tracks were again:
- Track 1: Zoom + Desktop Audio (7.1) + Desktop Audio (LR)
- Track 2: Zoom + Microphone + Desktop Audio (LR)
- Track 3: Zoom + Desktop Audio (LR)
Proof via math
I lied, by the way, about the math. Here's more math to prove this. Assume the following variables:
- T1...3 - The tracks in the MKV file.
- A - Zoom
- B - Desktop Audio (7.1)
- C - Desktop Audio (LR)
- D - Microphone



So, I want A, B, and D. Let's eliminate the simple
ones first. B and D can be extracted via:


C is simply B's first 2 audio channels (Front Left and Front
Right). So we don't need math for that. But we now have 2 ways to grab
A:



We have everything needed to recover all of the audio tracks. So time to
get to work. There's many of these files, and each of them are at least an
hour long. So loading 8 × 3 audio channels into Audacity would be
infeasible and inefficient. Time to automate it via FFmpeg.
Automation via FFmpeg
FFmpeg has a nice way to deal with processing of both audio and video.
"Intermediate Streams" can be created which apply effects to input. These
can be combined and mixed down into a final file. This is done via
-filter_complex. The command shown
above uses it to merge both inputs
into a single track via subtraction, and then exports the resulting
waveform to a file. Pretty nice stuff.
In the next few sections, I am going to format the commands as shell
scripts, just because it's easier to deal with -filter_complex
that way. I'll place a final command at the end of each though if you, by
some miracle, have the same problem as me and need it.
Extracting Microphone Audio
To do this, simply invert Track 3 and merge it with Track 2. Assuming an MKV file with 3 audio files, this is simple. Just a disclaimer, the input files are 7.1 surround, which have 8 channels. My microphone, the HyperX QuadCast S, records in stereo. So we only need the first 2 channels. The rest are thrown out. If your microphone records in mono, the command below should be adjusted accordingly.
#!/bin/bash
# Filter for second stream (1) 7.1 -> Stereo
F1S="[0:a:1]pan=stereo|c0=FL|c1=FR[1s]"
# Filter for third stream (2) 7.1 -> Stereo
F2S="[0:a:2]pan=stereo|c0=FL|c1=FR[2s]"
# Output Filter for second stream (1)
F1O="[1s][2s]amerge=inputs=2,pan=stereo|c0=c0-c2|c1=c1-c3[1o]"
ffmpeg \
-i "$1" \
-filter_complex "${F1S};${F2S};${F1O}" \
-map '[1o]' \
-c:a flac \
-compression_level 12 \
"mic_audio.flac"
So what's going on here? In FFmpeg syntax, [0:a:0] would be
the first audio stream in the MKV file. [0:a:1] would be the
second audio stream. And so on. We are making 2 intermediate streams
(1s and 2s) from the inputs, and 1 intermediate
stream (1o) from the first 2. With a diagram, it would look
like this:

All that [0:a:1]...[1s] does is extract the first 2 channels
from the second audio track in the file. The next filter,
[0:a:2]...[2s], does the same for the third audio track in the
file.
The third filter takes the two streams described above, s1 and
s2, and merges them via subtraction (again, essentially
inversion). This is done via amerge. The output is
1o, which is mapped as the export stream and then written to a
file.
For those who want to see this done in a single command:
UNIX> ffmpeg -i "file.mkv" -filter_complex "[0:a:1]pan=stereo|c0=FL|c1=FR[1s];[0:a:2]pan=stereo|c0=FL|c1=FR[2s];[1s][2s]amerge=inputs=2,pan=stereo|c0=c0-c2|c1=c1-c3[1o]" -map '[1o]' -c:a flac -compression_level 12 "mic_audio.flac"Extracting Desktop Audio (7.1)
To do this, simply invert Track 3 (again...) and merge it with Track 1. Making the same assumptions as when extracting the microphone audio, this is simple. However, the final file must have all 8 channels rather than stereo. This is just because 7.1 surround consists of 8 channels.
#!/bin/bash
# Filter for third stream (2) 7.1 -> Stereo
F2S="[0:a:2]pan=stereo|c0=FL|c1=FR[2s]"
# Output Filter for third stream (2)
F2O="[0:a:0][2s]amerge=inputs=2,pan=7.1|c0=c0-c8|c1=c1-c9|c2=c2|c3=c3|c4=c4|c5=c5|c6=c6|c7=c7[2o]"
ffmpeg \
-i "$1" \
-filter_complex "${F2S};${F2O}" \
-map '[2o]' \
-c:a flac \
-compression_level 12 \
"7.1_audio.flac"
This command uses only 2 intermediate filters. A bit easier to deal with.
It retains the same 2s filter from the previous section. Then
simply merges it with [0:a:0] (The first audio stream in the
MKV file) via inversion. I only perform subtraction on the first 2
channels, as shown in the pan filter: c0=c0-c8|c1=c1-c9|....
With a diagram, it would look like this:

For those who want to see this done in a single command:
UNIX> ffmpeg -i "file.mkv" -filter_complex "[0:a:2]pan=stereo|c0=FL|c1=FR[2s];[0:a:0][2s]amerge=inputs=2,pan=7.1|c0=c0-c8|c1=c1-c9|c2=c2|c3=c3|c4=c4|c5=c5|c6=c6|c7=c7[2o]" -map '[2o]' -c:a flac -compression_level 12 "7.1_audio.flac"Extracting Zoom Audio
Regarding the script above, 2o contains the full 7.1 desktop
audio stream completely separated. We can get "Desktop Audio (LR)" by
modifying the script above to extract the first 2 channels. Then it's as
simple as merging it with the first audio track [0:a:0] and
it's good to go. Zoom audio is mono, so we only need one of the two audio
tracks from the desktop audio to cancel out in [0:a:0].
#!/bin/bash
# Filter for third stream (2) 7.1 -> Stereo
F2S="[0:a:2]pan=stereo|c0=FL|c1=FR[2s]"
# Filter for Desktop Audio
F2O="[0:a:0][2s]amerge=inputs=2,pan=7.1|c0=c0-c8|c1=c1-c9|c2=c2|c3=c3|c4=c4|c5=c5|c6=c6|c7=c7[2o]"
# Output Filter for first stream (0)
F0O="[0:a:0][2o]amerge=inputs=2,pan=mono|c0=c0-2*c8[0o]"
ffmpeg \
-i "$1" \
-filter_complex "${F2S};${F2O};${F0O}" \
-map '[0o]' \
-c:a flac \
-compression_level 12 \
"zoom_audio.flac"Again, to visualise what's going on here:

Once again, here's a one-liner:
UNIX> ffmpeg -i "file.mkv" -filter_complex "[0:a:2]pan=stereo|c0=FL|c1=FR[2s];[0:a:0][2s]amerge=inputs=2,pan=7.1|c0=c0-c8|c1=c1-c9|c2=c2|c3=c3|c4=c4|c5=c5|c6=c6|c7=c7[2o];[0:a:0][2o]amerge=inputs=2,pan=mono|c0=c0-2*c8[0o]" -map '[0o]' -c:a flac -compression_level 12 "zoom_audio.flac"All filters in a single script/command
I could just have these scripts running, extract all three tracks out, and
then manually remux them into a new MKV via a second ffmpeg
command. But that's not very fun, nor is it optimal. It also requires disk
space. So, let's do everything in memory. Combining all of these into a
single script/command may sound daunting, but we'll work it out.
Input file streams (e.g. [0:a:0]) may be used more than once.
This was demonstrated in the script above. However, intermediate streams
can only be used once. To get around this,
asplit
can be used. It makes a filter have 2 (or more) outputs rather than one.
With that out of the way, here's the script:
#!/bin/bash
# Stereo Splices
F1S="[0:a:1]pan=stereo|c0=FL|c1=FR[1s]"
F2S="[0:a:2]pan=stereo|c0=FL|c1=FR,asplit[2sA][2sB]"
# Filter for Microphone Audio
F1O="[1s][2sA]amerge=inputs=2,pan=stereo|c0=c0-c2|c1=c1-c3[1o]"
# Filter for Desktop Audio
F2O="[0:a:0][2sB]amerge=inputs=2,pan=7.1|c0=c0-c8|c1=c1-c9|c2=c2|c3=c3|c4=c4|c5=c5|c6=c6|c7=c7,asplit[2o][DA]"
# Output Filter for first stream (0)
F0O="[0:a:0][DA]amerge=inputs=2,pan=mono|c0=c0-2*c8[0o]"
ffmpeg \
-i "$1" \
-filter_complex "${F1S};${F2S};${F1O};${F2O};${F0O}" \
-map 0:v \
-map '[0o]' \
-map '[1o]' \
-map '[2o]' \
-c:v copy \
-c:a flac \
-compression_level 12 \
-metadata:s:a:0 title="Zoom Broadcast Audio" \
-metadata:s:a:1 title="Voice - iDestyKK" \
-metadata:s:a:2 title="7.1 Desktop Audio" \
"$2"
Here, the order of how the filters are defined in the
-filter_complex call is actually important. F0O
must come after F2O, as it requires an intermediate
stream from that filter.
I moved [0:a:0] to the far right to prevent arrow/line
intersections. Without that, the initial graph looked pretty ugly. The
splits are notated with circles. You can see the arrow splitting into two
there. I think that's as obvious as it gets.

You know what comes next. Here's a one-liner. Complex FFmpeg commands get very lengthy, and this is a pretty good example of one:
UNIX> ffmpeg -i "file.mkv" -filter_complex "[0:a:1]pan=stereo|c0=FL|c1=FR[1s];[0:a:2]pan=stereo|c0=FL|c1=FR,asplit[2sA][2sB];[1s][2sA]amerge=inputs=2,pan=stereo|c0=c0-c2|c1=c1-c3[1o];[0:a:0][2sB]amerge=inputs=2,pan=7.1|c0=c0-c8|c1=c1-c9|c2=c2|c3=c3|c4=c4|c5=c5|c6=c6|c7=c7,asplit[2o][DA];[0:a:0][DA]amerge=inputs=2,pan=mono|c0=c0-2*c8[0o]" -map 0:v -map '[0o]' -map '[1o]' -map '[2o]' -c:v copy -c:a flac -compression_level 12 -metadata:s:a:0 title="Zoom Broadcast Audio" -metadata:s:a:1 title="Voice - iDestyKK" -metadata:s:a:2 title="7.1 Desktop Audio" "new.mkv"At this length, FFmpeg commands are better off being split into variables. The bash script variant is easily much more readable than this one-liner.
"Why FFmpeg over Audacity? It's way too complicated!"
Subjective. Automation runs my life. Would you rather manually load in tens of MKV files into Audacity and do the filters yourself? Or, would you let a script do it for you? Loading a single MKV into Audacity (8 × 3 = 24 audio channels total) took nearly 3 minutes because it was over an hour long. Combine the time it would take to apply the filters and export, and that's around 5 minutes per file, and you have to interact with each and every file and filter. I hope you have no plans for that afternoon.
The FFmpeg approach? It crushed each file in under 30 seconds, and no interaction was required on my part. It took me under 5 minutes to write the script as well. I think that's well worth it. While it was crunching away at the files, I was doing other things. But, to each their own.
Results
Well, I'm glad that mess is fixed. Not only did the script fix the audio,
but it also optimised the filesize of the MKVs, reducing the size by
more than half. Originally, there were 3 7.1 surround sound streams
in there (24 audio channels total). The size of those audio streams was
more than the one video stream of the lecture. The final MKVs have a mono
track, a stereo track, and a 7.1 surround sound track (11 audio channels
total). And it's been repacked with better compression via FFmpeg's
-compression_level 12 flag. No data was lost. Now that's some
optimal archival.
I don't usually check lecture recordings. That's why it took so long for me to notice a mistake in the audio. However, recently I gave a talk over Zoom, which I recorded. So, finding out that the audio was messed up gave me quite a scare. I'm glad it, and the other videos, are properly and losslessly recovered.
